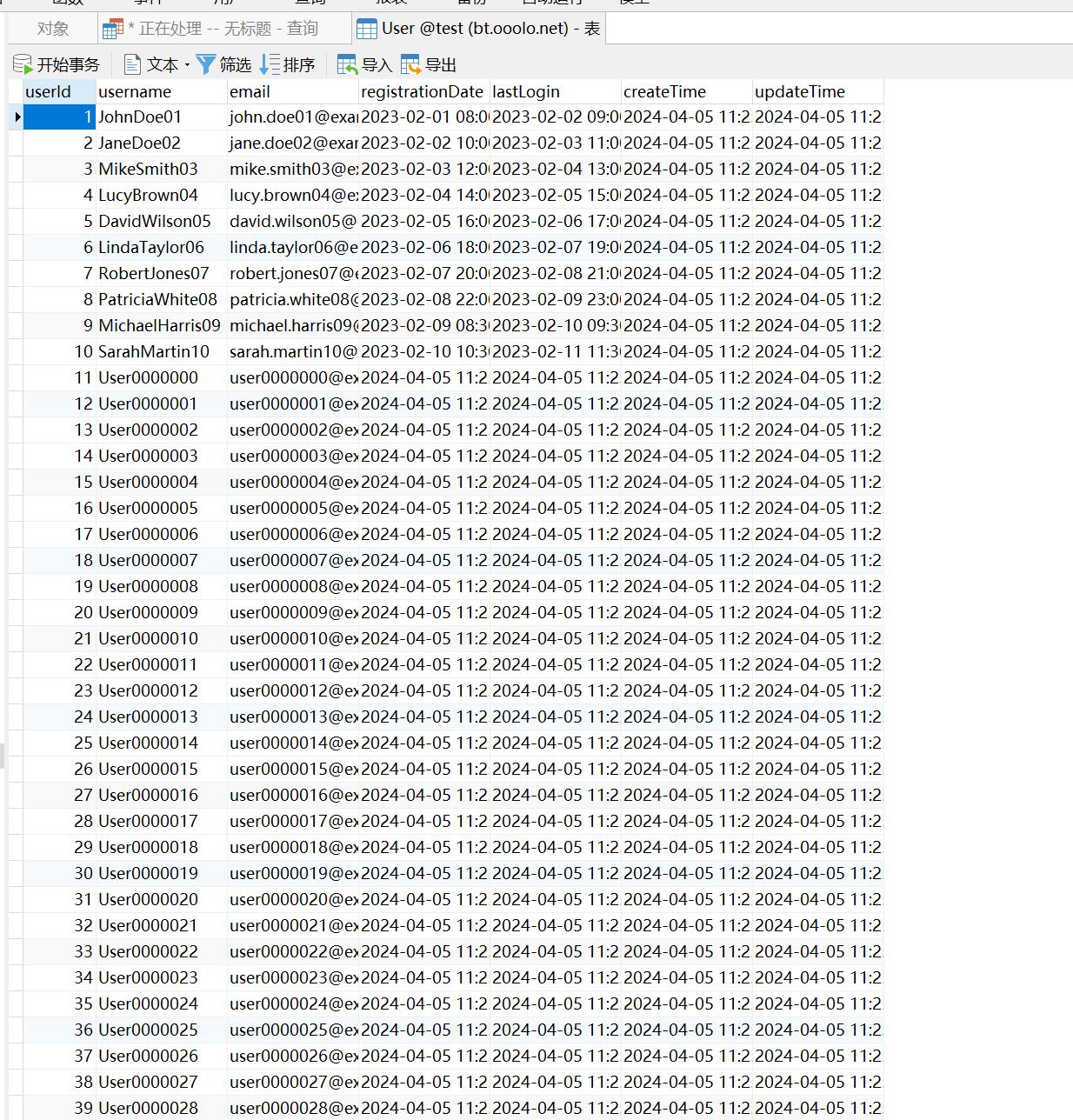
步骤1、安装好clickhouse数据库
https://ooolo.net/article/442.html
步骤2、安装etl中间件ClickHouse JDBC Bridge
Clickhouse-jdbc-bridge:是clickhouse提供的一个jdbc组件,用于通过JDBC的方式远程访问其他数据库表。
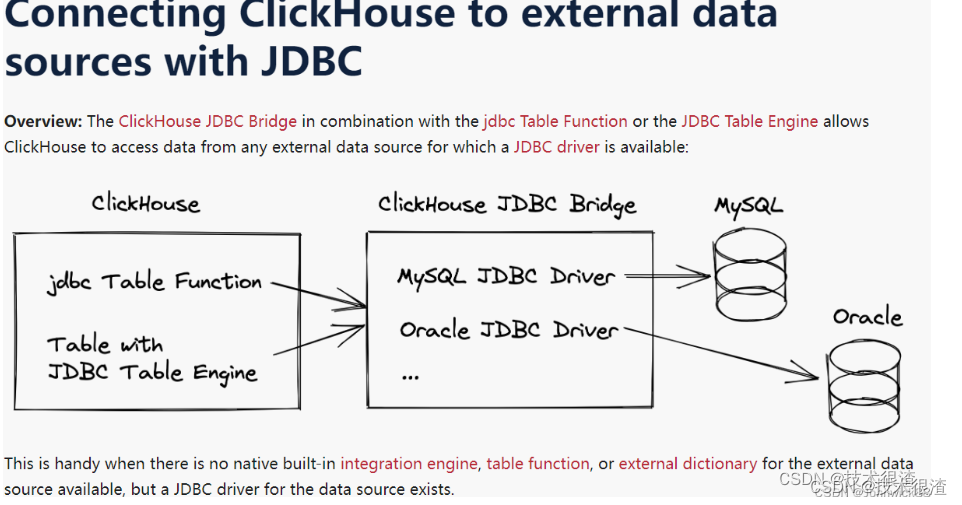
Clickhouse支持通过JDBC连接外部数据库,所有支持JDBC驱动的数据库都能直接接入clickhouse。要实现JDBC连接,clickhouse需要使用以后台进程运行的程序 clickhouse-jdbc-bridge。
JDBC表引擎可以对接Mysql、Postgresql、SQLite等数据库,但是JDBC表引擎不能单独完成对接工作,需要依赖clickhouse-jdbc-bridge的查询代理服务,clickhouse-jdbc-bridge是java语言实现的sql代理服务,项目地址为:
https://github.com/ClickHouse/clickhouse-jdbc-bridge #作者的资源库有直接可以去下载RPM安装包
https://clickhouse.com/docs/zh/engines/table-engines/integrations/jdbc # clickhouse官网的介绍

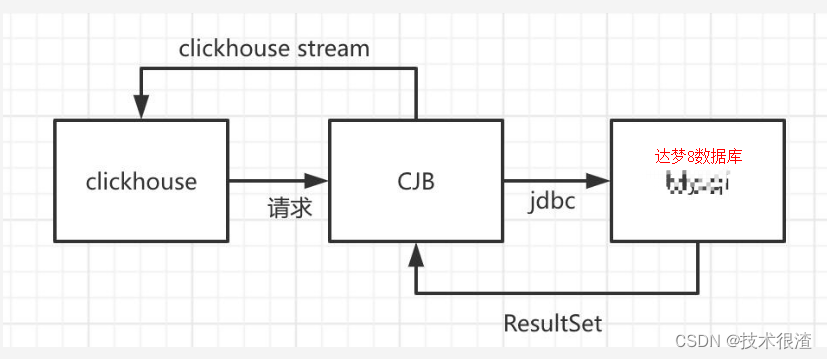
我们看懂架构图,则需要保证
ClickHouse JDBC Bridge第三方插件要能正常连接到2个数据库。我们可以把这个插件看出是2个数据库直接的桥梁!
达梦8数据库肯定是完整支持jdbc协议的,所以这个就存在2个数据库数据类型的一一映射关系,这个关系,就在ClickHouse JDBC Bridge维护。
步骤3、ClickHouse JDBC Bridge安装部署方法
(1)在官网:https://github.com/ClickHouse/clickhouse-jdbc-bridge,
下载源码程序到本地,通过在idea或者eclipse中执行mvn的clean、packge完成打包后,到打包目录里面找到clickhouse-jdbc-bridge-2.0.7-shaded.jar。
也可以下载编译好的包。。
(2)将clickhouse-jdbc-bridge-2.0.7-shaded.jar
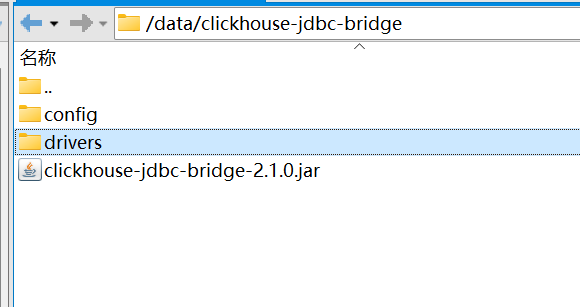
放在Linux服务器的目录/data/clickhouse-jdbc-bridge下,并在该文件同级目录下新建两个目录:
config/datasources --存放数据源配置文件
drivers --jdbc驱动存放目录
(3)以连接JDBC访问Oracle 11g为例:
①在官网https://mvnrepository.com下载Oracle对应的驱动包ojdbc8-12.2.0.1.jar放置到/data/clickhouse-jdbc-bridge/drivers目录下。
②设置clickhouse-jdbc-bridge远程的数据库信息
mkdir -p config/datasources #创建config目录及其子目录
在datasources目录下创建数据源配置文件,msjdbc.json文件名尽量与配置中的datasource名一致,如下配置:
{
"msjdbc": {
"driverUrls": [
"/data/clickhouse-jdbc-bridge/drivers/ojdbc8-12.2.0.1.jar"
],
"driverClassName": "oracle.jdbc.driver.OracleDriver",
"jdbcUrl": "jdbc:oracle:thin:@远程连接的数据库ip:端口:服务名",
"username": "账号",
"password": "密码",
"connectionTestQuery": ""
}
}
当前Linux服务器的目录为:
|--data
|--clickhouse-jdbc-bridge
|--clickhouse-jdbc-bridge-2.0.7-shaded.jar
|--noput.out
|--drivers
|--ojdbc8-12.2.0.1.jar
|--config
|-- datasources
|-- msjdbc.json
③运行clickhouse-jdbc-bridge
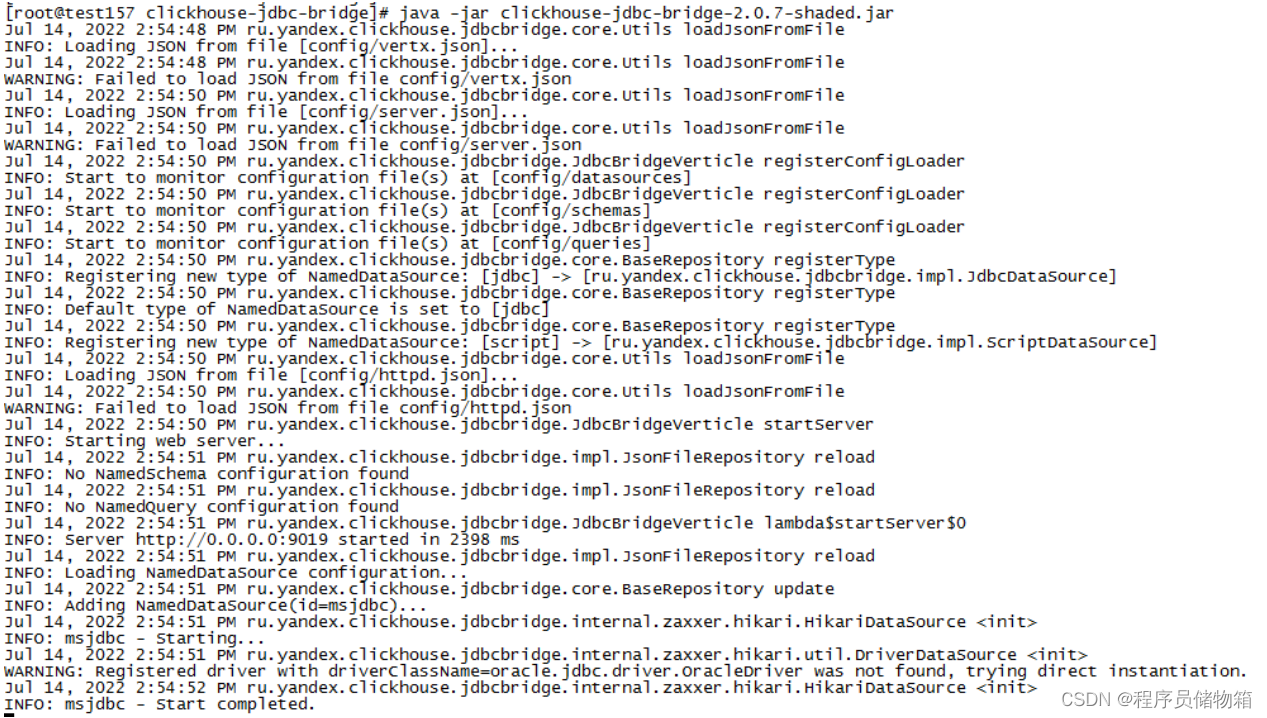
nohup java -jar clickhouse-jdbc-bridge-2.0.7-shaded.jar &
tail -f nohup.out
成功启动:
④在clickhouse部署的那台服务器中
到/etc/clickhouse-server目录下的config.xml文件,找到以下代码,移除注释,并修改host为执行clickhouse-jdbc-bridge-2.0.7-shaded.jar的ip地址:
<jdbc_bridge>
<host>XX.XX.XX.XX</host>
<port>9019</port>
</jdbc_bridge>
保存之后,重启clickhoust服务
systemctl restart clickhouse-server
3、访问
(1)查看能成功访问的的链接:select * from jdbc('','show datasource')
(2)远程查询oracle的某个表
select from jdbc('msjdbc', 'select * from test_tb')
(3)直接远程连接
select from jdbc('jdbc:oracle:thin:账号/密码@xx.xx.xx.xx:端口/服务名', 'select * from test_tb')